机器学习
- 关系图
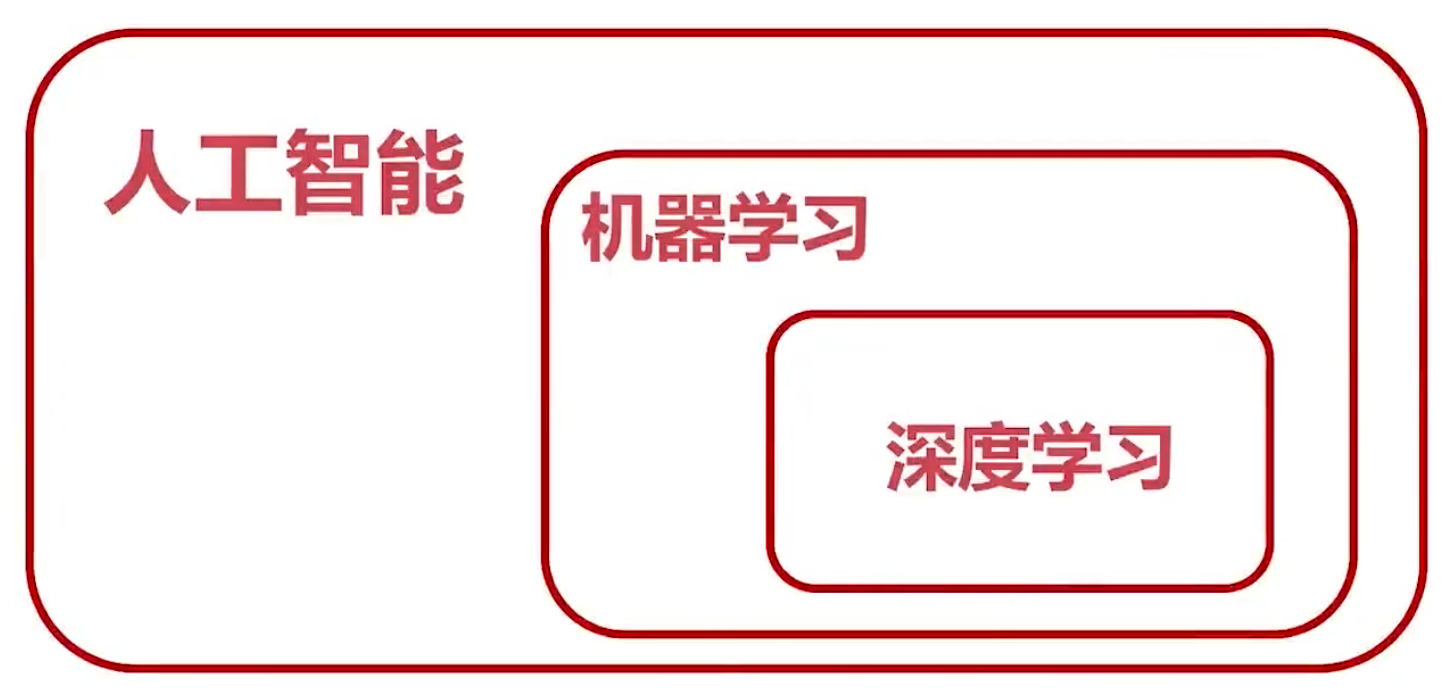
关系图,深度学习是机器学习的一种方法 - 计算机视觉与机器学习的关系
- 计算机视觉是机器学习的一种应用,而且是最有价值的应用。
Haar人脸、眼、鼻、口识别
- OpenCV有两种识别方法
- 哈尔(Haar)级联方法
- Haar是专门为解决人脸识别而推出的
- 在深度学习还不流行时,Haar已经可以商用
- 深度学习方法(DNN)
- 哈尔(Haar)级联方法
- Haar人脸识别步骤
- 创建Haar级联器
- 导入图片并将其灰度化
- 调用detectMultiScale方法进行人脸识别
- API:
detectMultiScale(img, double scaleFactor = 1.1, int minNeighbors = 3)img: 图像scaleFactor: 缩放因子minNeighbors: 最小的像素值
- API:
-
图像识别
-
视频识别
Haar+Tesseract进行车牌识别
- mac 安装 Tesseract:
brew install tesseract tesseract-lang - bash操作读取图片:
tesseract ***.png rename - 车牌预处理包括的内容
- 对车牌进行二值化处理
- 进行形态学处理
- 滤波去噪点
- 缩放
深度学习基础知识
- 深度学习是计算机视觉最为重要的方法
- 深度学习网络模型
- DNN(Deep Neutral Network,深度神经网络)
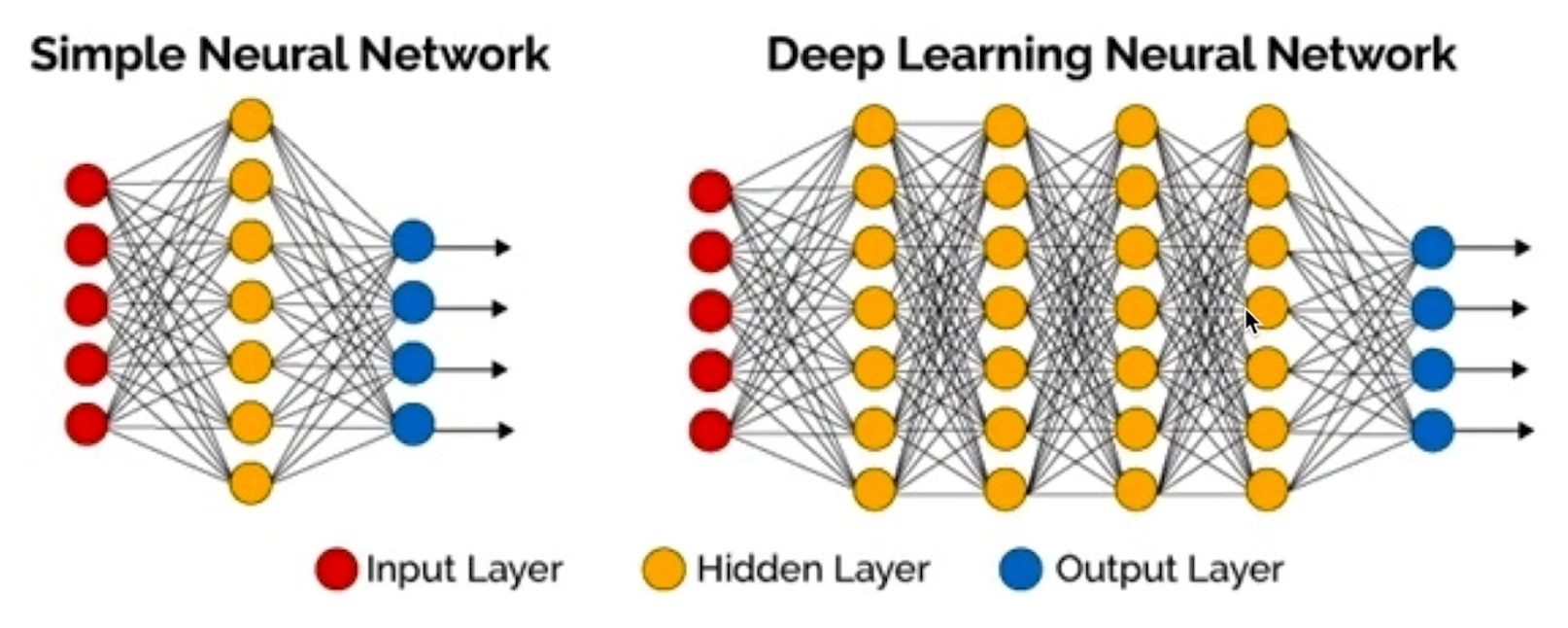
DNN(红色输入层,黄色隐藏层,蓝色输出层) - RNN(Recurrent Neural Network,循环神经网络)
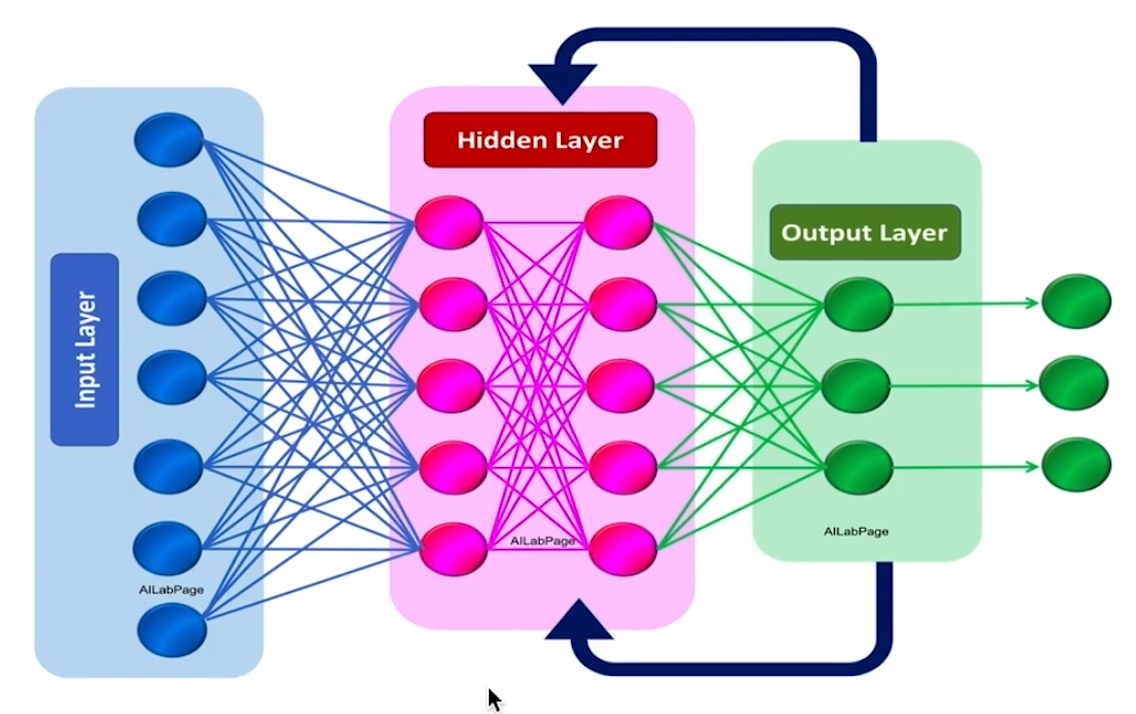
RNN(常用于语音识别,机器翻译,生层图像描述) - CNN(Convolutional Neural Network,卷积神经网络)
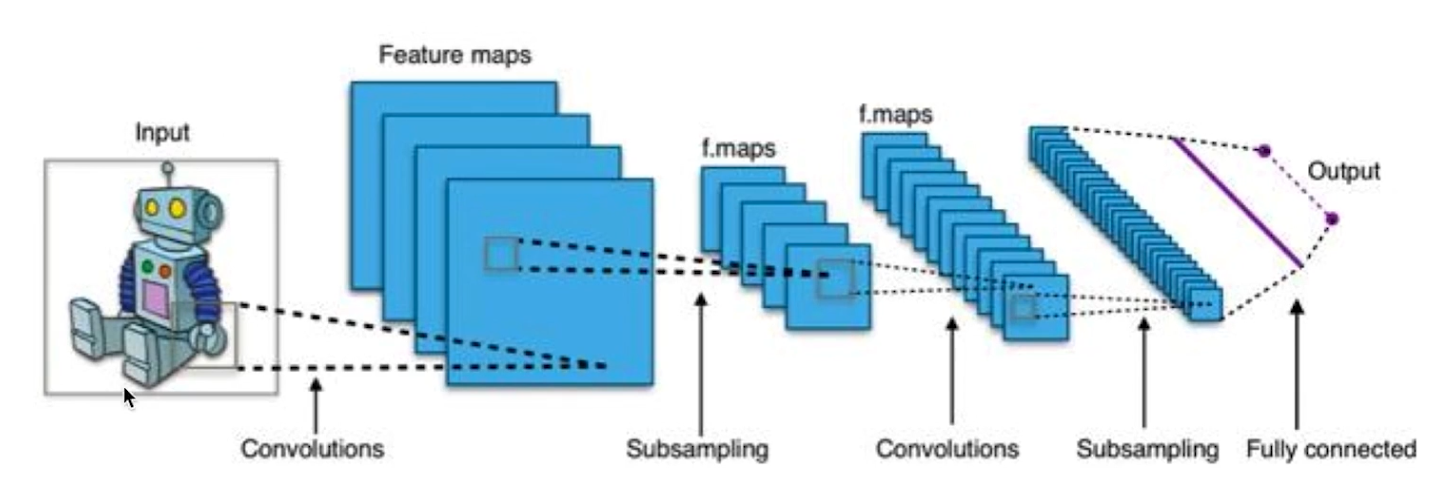
CNN(对图像卷积,拆分,卷积... 归类特征点,常用于图片分类、检索,目标定位检测,目标分割)
- DNN(Deep Neutral Network,深度神经网络)
- 几种CNN网络实现
- LeNet,1998年第一代CNN,28x28手写字
- AlexNet,2012年ImageNet
- VGG、GoogleLeNet、ResNet
- ResNet:图像错误率识别达到了低于3.6%
- 几种CNN目标检测网络实现
- RCNN、Fast RCNN、Faster RCNN
- SSD(Single Shot Detectors)
- YOLO、YOLOv2...YOLOv5:该方案是目前速度最快的
- 深度学习库
- TensorFlow Google
- caffe—>caffe2->torch(pytorch) 贾扬清
- MXNet Apache
- 训练数据集
- MNIST、Fashion-MNIST 手写字体
- VOC,举办挑战赛时的数据集,2012年后不再举办(不推荐)
- COCO,用于目标检测的大型数据集(推荐)
- ImageNet(推荐)
- 训练模型
- TensorFlow训练出的模型是
.pb文件 - Pytorch训练出的模型是
.pth - Caffe训练出的模型是
.caffe - ONNX开放性神经网络交换格式
.onnx(目的是为了统一格式)
- TensorFlow训练出的模型是
- OpenCV对DNN的支持
- OpenCV只能使用DNN,不能训练DNN模型
- OpenCV支持的模型
- TensorFlow
- Pytorch/torch
- Caffe
- DarkNet:产生的数据模型就是YOLO,目前速度最快的目标检测方式
dnn实现图像分类
- OpenCV使用DNN
- 读取模型(TensorFlow、YOLO...),并得到深度神经网络
- 读取图片 / 视频
- 将图片转成张量,送入深度神经网络
- 进行分析,并得到结果
- OpenCV导入模型
- readNetFromTensorflow
- readNetFromCaffe
- readNetDarknet, YOLO
- readNet(自动识别模型)
- 导入模型API参数
readNetFromTensorflow(model, config)readNetFromCaffe/Darknet(config, model)readNet(model, [config, [framework]])
- 如何读取图片并把图像转换成张量
- blobFromImage函数
blobFromImage(image, scalefactor = 1.0, size = Size(), mean = Scalar(), swapRB = false, crop = false)image: 图片scalefactor: 缩放因子,默认1.0 不进行缩放size: 指定图像的大小mean: 整体像素值减去平均值,是一个RGB的三元组,作用是消除图像中光照的变化,对ImageNet数据集来说,他给定的均值是103、116、123(R, G, B)mean的含义,当左侧图像通过减去均值就会是右侧图像,右侧图就不太受光照的影响了,这样更有利于我们图像的分析。
swapRB: RB 是否交换,对于OpenCV来说默认是BGR的,对于深度学习模块来说可能是RGB也可能是BGR,所以这个时候就是R与B是否进行交换。默认情况下是不交换的。crop: 是否进行裁剪,如果我们输入图像是640 x 480的,但是网络模型要求的是300 x 300的,这个时候我们是否以图像中心为中心对图像进行裁剪,把它超出的部分都裁剪了。默认值是false不进行裁剪。
- 将张量送入网络并执行
net.setInput(blob): 将我们得到的张量blob塞给网络net.forward(): 使用网络自动分析