一条语句是如何执行的
一条SQL语句的执行过程涉及多个阶段,从客户端发起请求到服务器处理并返回结果,整个过程可以大致分为以下几个步骤:
客户端请求 -> 连接管理 -> SQL解析 -> 查询优化 -> 查询执行 -> 结果处理与返回
客户端请求
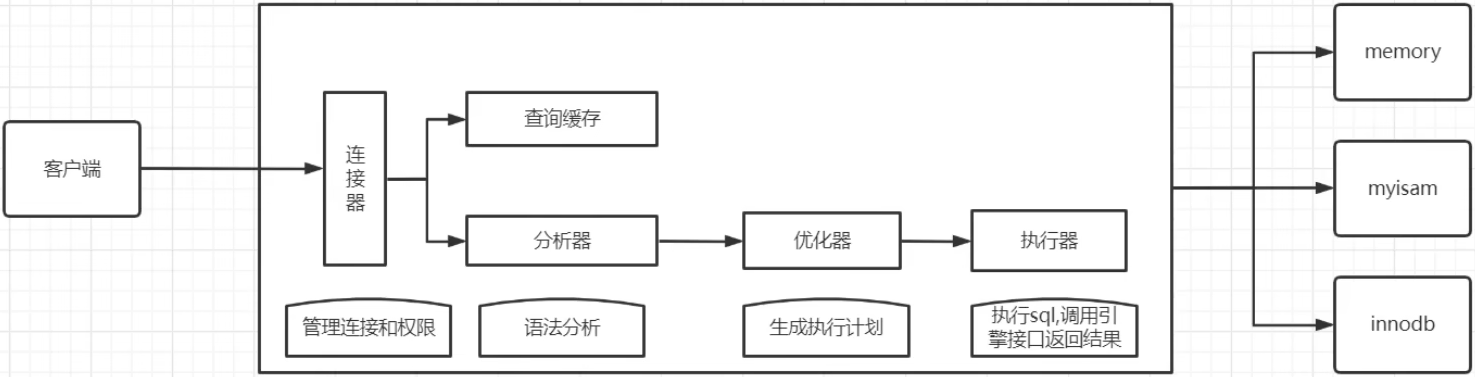
- 客户端(如数据库管理工具、应用程序等)通过MySQL客户端或应用程序向MySQL服务器发送SQL查询请求。
连接管理
- MySQL服务器接收到请求后,会首先检查客户端的身份验证信息,确保客户端有权限连接到服务器。
- 如果身份验证通过,服务器会为该连接分配一个线程,用于后续的处理过程。
SQL解析
- 解析器(Parser):检查SQL语句的语法是否正确,包括关键词的拼写、表名、列名等是否存在错误。如果语法正确,解析器会将SQL语句转换成内部数据结构(如解析树)。
- 预处理器(Preprocessor):进一步检查解析树中的表名、列名等是否存在,并进行权限验证。如果预处理通过,SQL语句会被转换成更优化的内部表示形式。
查询优化
- 优化器(Optimizer):根据不同的执行计划(Execution Plan)来选择最佳的执行路径。优化器会考虑索引、表扫描、排序、合并等多种因素,以提高查询效率。优化器会生成一个查询执行计划,这个计划决定了查询的具体执行方式。
查询执行
- 执行器(Executor):根据优化器生成的执行计划来实际执行查询操作。执行过程中,执行器会调用存储引擎(Storage Engine)来进行数据检索、插入、更新或删除等操作。
- 存储引擎:负责实际的数据存取操作,MySQL支持多种存储引擎(如InnoDB、MyISAM等),不同存储引擎具有不同的特性和优化方式。存储引擎会根据执行器的指令,访问数据库文件并返回结果。
结果处理与返回
- 执行器将存储引擎返回的结果进一步处理(如排序、过滤等),并生成最终的查询结果。
- 最终的查询结果通过服务器发送回客户端。
- 具体的SQL语句执行顺序(以SELECT查询为例)
-
- 虽然SQL语句的书写顺序和逻辑顺序可能有所不同,但实际的执行顺序通常遵循以下规则:
FROM/JOIN:首先确定要从哪些表中检索数据,以及表之间的连接关系。WHERE:根据指定的条件过滤出符合条件的记录。GROUP BY:将过滤后的记录按照指定的列进行分组。HAVING:对分组后的数据进行过滤,确保只保留满足条件的分组。SELECT:选择需要显示的列,并对数据进行聚合计算(如COUNT、SUM等)。DISTINCT:如果指定了DISTINCT,则对查询结果进行去重处理。ORDER BY:根据指定的列对查询结果进行排序。LIMIT:限制返回的记录数。- 需要注意的是,虽然SQL语句的书写顺序可能允许先写SELECT再写FROM等,但实际的执行顺序是固定的,这有助于理解SQL查询的底层工作原理。